昨天有說到 RAG 的效能衡量可以分成兩大類,今天就是要先介紹檢索指標(Retrieval metrics)。
我們不需要把檢索和生成混在一起看,而是可以單獨檢查檢索器,看它給出的結果有沒有符合查詢、是不是把正確的資料找回來了。
下面就讓我們來一一介紹。(雖然想放好看的中文公式,但好像不支援,所以這邊會解釋的比較多 TT)
公式:
系統判為「相關」而被取回的數量(Predicted Positive) = TP + FP
文件總數 = TP + TN + FP + FN
我們先詳細的說明每個英文代表的意思:
我知道這樣聽起來有點饒口,不然我們就用舉例來說明,台北的店家有很多,其中有些店家「真的在賣肉燥飯」= 相關文件,有些店家「沒有賣肉燥飯」= 不相關文件,假設我們現在要找「有賣肉燥飯的店家」,我們從找到資料來判斷他是哪種情況。
| . | 系統判定:相關(有推薦) | 系統判定:不相關(沒推薦) |
|---|---|---|
| 實際有賣肉燥飯 | TP(推薦對了) | FN(漏掉了) |
| 實際沒賣肉燥飯 | FP(誤導了) | TN(忽略對了) |
相信我解釋了這麼多應該也知道這個要表達的意義是甚麼了,畢竟他在這個公式上面也比較直觀,就是要找到正確預測的狀態,不過他也不是主要的檢索指標,畢竟在大型知識庫裡,TN 會非常多,就算他的 TP 很少也會因為 TN 數值較大而誤判這系統的準確率是高的。
公式:
英文意思都在上面了,這邊我就不多做說明了,而這個數值要反映的是檢索到的文件(TP+FP)中,有多少比例與我們的查詢是真的相關(TP),他比較關注的是我們檢索的品質。
延續我們之前的例子,假如系統推薦了 10 間店(TP+FP = 10),其中有8 間真的有賣肉燥飯(TP = 8),2 間其實是雞排店(FP = 2)。
代表他其實給的挺準的,很少是我不要的東西。
公式:
這其實就是精確率的變形,差別就在於它只關注「前幾個」結果,我們之前在實作 RAG 的時候也有設定過要返回前幾個最相關的答案,所以 Precision@k 特別重要;它也能公平比較不同系統,因為他們檢索的結果數量其實不見得會是一樣的。
公式:
雖然他長得跟精確率可能很像,但其實還是有點不一樣噢!
召回率必須知道「相關文件的總數」,但在大型系統中(知識庫文件數量多),這部分的取得會變得相當困難。
召回率其實就是在表示所有相關的文件中(TP+FN),他成功的找回多少(TP),其實也有前 k 筆召回率,不過就跟前 k 筆精確率一樣,就在原先的基礎加入了只關注前幾筆這樣。
這邊有一張圖來表示不同精確率與召回率的組合情境: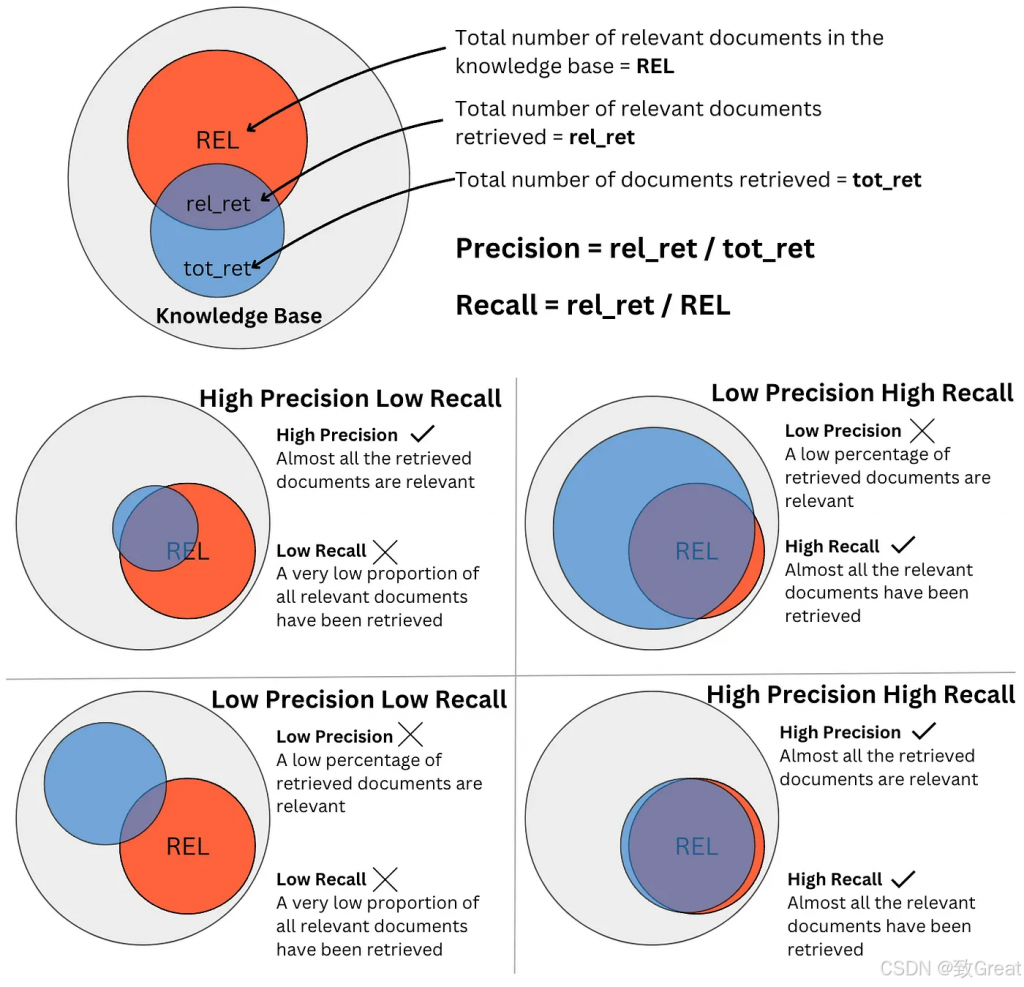
圖片來源:RAG科普文!检索增强生成的技术全景解析
這邊來幫忙翻譯一下:
REL = 所有相關文件(紅色區域)
rel_ret = 檢索到的相關文件(交集)
tot_ret = 檢索到的文件總數(藍圈)
這邊展示了四個情境:
High precision, low recall(高精確率、低召回率)
只取回少量、非常確定的結果(只取回 5 筆,其中 4 筆相關、1 筆不相關)
可能原因:k 值設太小、相似度門檻太嚴謹,容易漏掉關鍵依據
Low precision, high recall(低精確率、高召回率)
大量取回,幾乎把相關都撈到,但也夾了很多不相關
可能原因:k 設太大、門檻太寬;常見對策:先撈多提高 Recall,再用 re-ranker 提升 Precision
Low precision, low recall(低精確率、低召回率)
取回少又髒:關鍵沒撈到(FN 多),撈到的還多半不相關(FP 多)
可能原因: 查詢不好、索引壞、語言/分詞出錯、資料品質差。
High precision, high recall(高精確率、高召回率)
取回既全面又乾淨:幾乎所有相關都撈到,且幾乎都是真正相關
常見做法:混合檢索(BM25+向量)+ 重排序器 + 合理的 k。
感覺今天要講完全部好像太多了,可能後面還會分成 1 ~ 2 篇解釋一下,今天先這樣啦~~~~

